


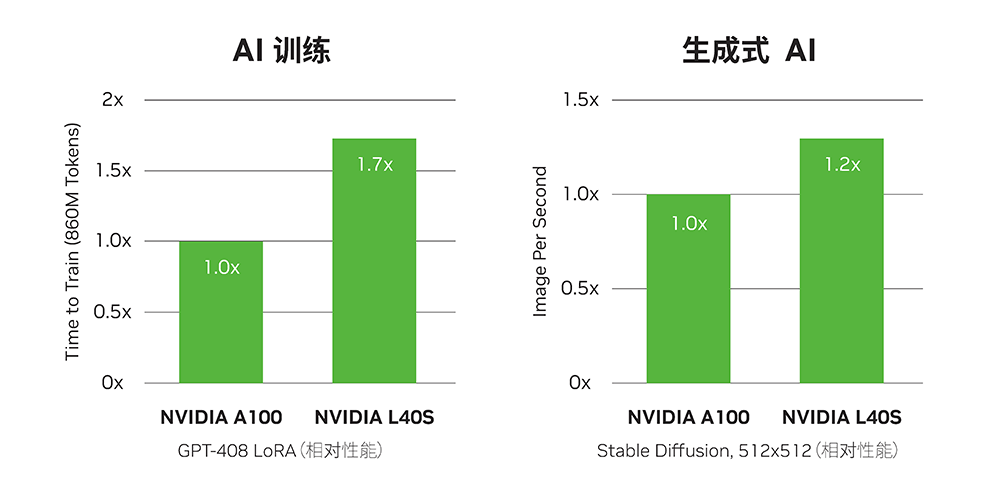









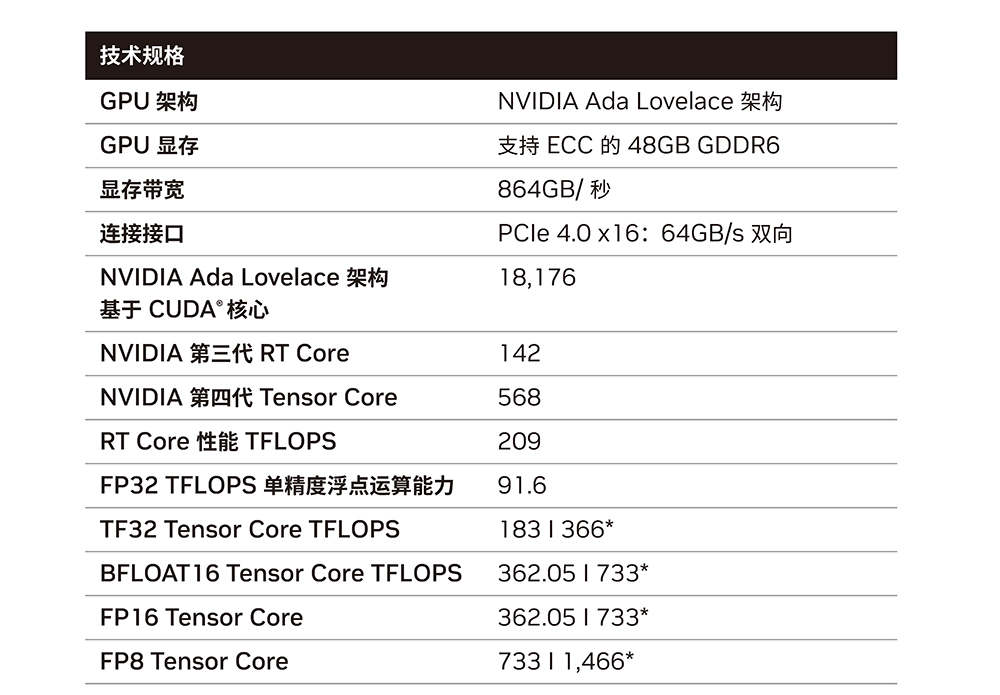
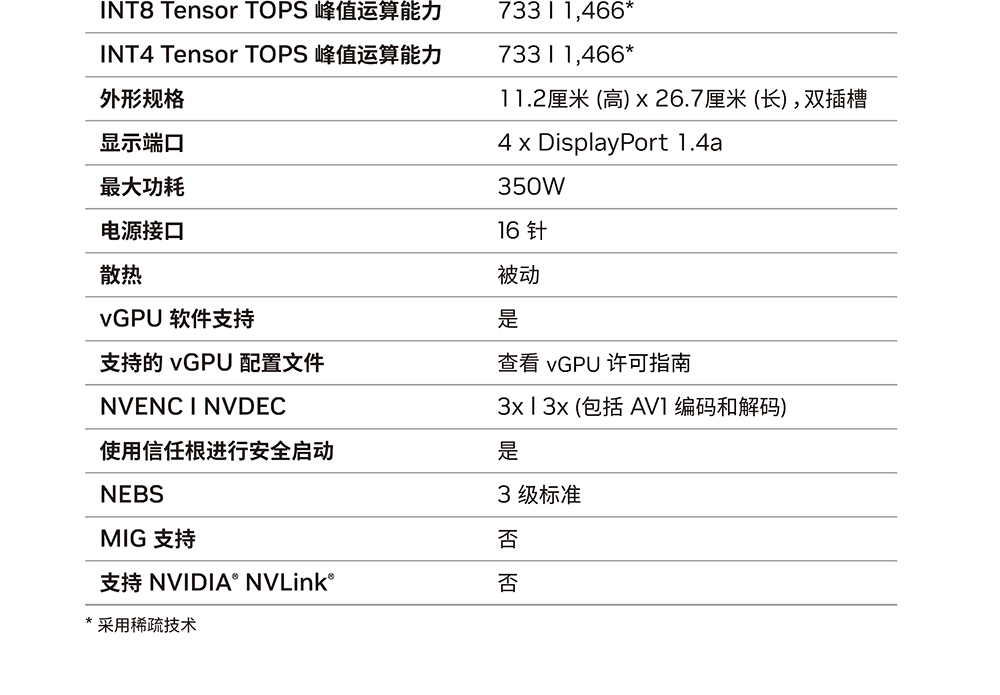
NVIDIA L40S Specifications
| L40S | A100 80GB SXM | |
|---|---|---|
| Best For | Universal GPU for Gen AI | Highest Perf Multi-Node AI |
| GPU Architecture | NVIDIA Ada Lovelace | NVIDIA Ampere |
| FP64 | N/A | 9.7 TFLOPS |
| FP32 | 91.6 TFLOPS | 19.5 TFLOPS |
| RT Core | 212 TFLOPS | N/A |
| TF32 Tensor Core | 366 TFLOPS | 312 TFLOPS |
| FP16/BF16 Tensor Core | 733 TFLOPS | 624 TFLOPS |
| FP8 Tensor Core | 1466 TFLOPS | N/A |
| INT8 Tensor Core | 1466 TOPS | 1248 TFLOPS |
| GPU Memory | 48 GB GDDR6 | 80 GB HBM2e |
| GPU Memory Bandwidth | 864 GB/s | 2039 GB/s |
| L2 Cache | 96 MB | 40 MB |
| Media Engines | 3 NVENC(+AV1) 3 NVDEC 4 NVJPEG |
0 NVENC 5 NVDEC 5 NVJPEG |
| Power | Up to 350 W | Up to 400 W |
| Form Factor | 2-slot FHFL | 8-way HGX |
| Interconnect | PCle Gen4 x 16: 64 GB/s | PCle Gen4 x 16: 64 GB/s |

